Kesähessujen suositukset
Kirjoittaja Risto Tuomainen toimi kesäharjoittelijana Ylen verkkovälinekehitystiimissä. Tiimiin kuului myös Henri Ståhl ja Jarkko Tuovinen.
Internetin avulla on helppo ylläpitää niin laajaa tuotekatalogia, ettei käyttäjän ole käytännössä mahdollista tutustua kuin pieneen osaan siitä. Erilaiset suosittelualgoritmit ovat monien palveluiden käyttämä tapa päihittää tämä runsaudenpula. Onkin käyttökokemuksen kannalta erittäin hyödyllistä, mikäli nokkela algoritmi osaa löytää käyttäjän puolesta tätä kiinnostavia sisältöjä ja näin säästää häneltä työlään etsiskelyn vaivan.
Myös Yle tarjoaa Areenassa käyttäjilleen näennäisen loputtoman listan erilaisia ohjelmia, joiden seulomisessa suosittelukone olisi paikallaan. Vaikka tässä Yle kohtaa saman yleisen ongelman kuin kaikki suosittelujärjestelmiä rakentavat yritykset, Areenan aineistot muodostavat monella tavalla erityisen haasteen suosittelujen kannalta: katalogi vaihtuu jatkuvasti, katalogi on sisällöiltään hyvin heterogeeninen ja osa sisällöstä on hyvin sidottu tiettyyn ajankohtaan. Esimerkiksi vanhoja uutisia ei pitäisi suositella kenellekään, vaikka ne ovatkin olleet hyvin suosittuja sisältöjä. Toisaalta tuoreita uutisia voi hyvinkin suositella, mutta niitäkin vain katsojille joita ylipäänsä kiinnostavat uutislähetykset.
Kolmen kesäharjoittelijan tiimimme saikin tehtäväkseen kokeilla erilaisia suosittelualgoritmeja ja katsoa, minkälaisia suosituksia ne saisivat Ylen datoista aikaan.
Ensimmäinen roiskaisumme oli satunnaisten katsottavissa olevien ohjelmien suositteleminen. Tämän tarkoituksena oli lähinnä saada pystyyn ohjelmointirajapinta, joka osaa antaa edes jotakin suosituksia. Silloin emme vielä asiaa aavistaneet, mutta kesän kuluessa kävi ilmi, että satunnaissuosittelijaa varten kokoon kyhätty arkkitehtuuri muuttui toiminnallisuuden monimutkaistuessa läpitunkemattomaksi viidakoksi R-skriptejä ja csv-tiedostoja.
Askel satunnaissuosittelusta eteenpäin oli suosittujen ohjelmien suosittelu. Nämä kaksi triviaalia algoritmia myös havainnollistavat hyvin suositteluun liittyviä vaihtokauppoja: suosittelemalla täysin satunnaisesti saadaan esiin hyvin vähän katsottuja katalogin ohjelmia ja suositukset ovat mahdollisimman yllättäviä. Toisaalta suosituksista kelpo osa on käyttäjän kannalta hyödyttömiä, sillä kutakin käyttäjää kiinnostaa vain pieni osa kaikista sisällöistä. Sen sijaan suosittelemalla pelkkiä hittejä saadaan käyttäjälle tarjottua varsin todennäköisesti ohjelmia, joista hän pitää. Toisaalta hittien suosittelu ei täytä kovinkaan hyvin suosittelukoneen tärkeintä tehtävää, käyttäjälle tuntemattomien sisältöjen nostamista esiin.
Tietysti satunnaissuosittelu ja suosittujen ohjelmien suosittelu eivät olleet kumpikaan kummoisia, koska ne suosittelivat samalla tavalla jokaiselle käyttäjälle. Suosittujen ohjelmien suosittelusta oli kuitenkin lyhyt matka hieman vahvempaan suosittelualgoritmiin, jolle annoimme nimen popular v2. Popularv2 perustui käyttäjän viimeksi näkemään ohjelmaan. Algoritmi etsi ne muut käyttäjät, jotka myös olivat nähneet tämän ohjelman, ja suositteli sitten näiden käyttäjien parissa suosituimpia ohjelmia. Tämä osoittautui suoraviivaisesti otteestaan huolimatta yllättävän kiinnostavaksi ideaksi, ja tuotti jo aivan kelpo suosituksia.
Neljäntenä suosittelualgoritmina käytimme Collaborative Filtering -algoritmia (CF). CF oli muita menetelmiä huomattavasti sofistukoituneempi, ja osasi käyttää hyödykseen käyttäjän koko katseluhistoriaa. Hienostuneisuudestaan huolimatta se oli myös hyvin helppo toteuttaa, sillä tunnettuna algoritmina sen toteutus löytyi suoraan Sparkin MLlib-kirjastosta. Näennäiseen helppouteen liittyi kuitenkin omat sudenkuoppansa. Yhdessä vaiheessa esimerkiksi huomasimme, että CF-suosittelija tyrkytti jokaiselle käyttäjälle katseluhistoriasta riippumatta lastenohjelmia. Tietysti lastenohjelmat ovat kasvattavaa ja tervehenkistä viihdettä myös varttuneemmille katsojille, mutta pelkkien lastenohjelmien suositteleminen aina ja kaikille vaikutti silti hieman liialliselta. Yritys saada CF suosittelemaan muutakin johti melko pitkään sivupolkuun. Käsin kokeilemalle kävi ilmi, että eräs mallin toimintaa säätelevä parametri vaikuttaa ratkaisevasti suositusten laatuun, ja että käyttämämme arvo ei ollut lainkaan hyvä. Tämä sai loogisen selityksen, kun huomasimme, että Sparkin-dokumentaatiossa olleessa koodiesimerkissä ehdotettu 0.01 oli ilmeisesti kirjoitusvirhe ja yleensä vastaavana lukuna käytetään esim. kymmentä.
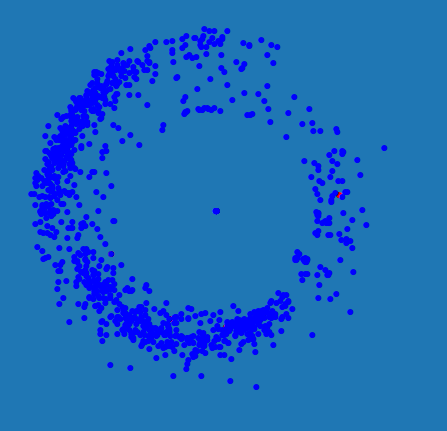
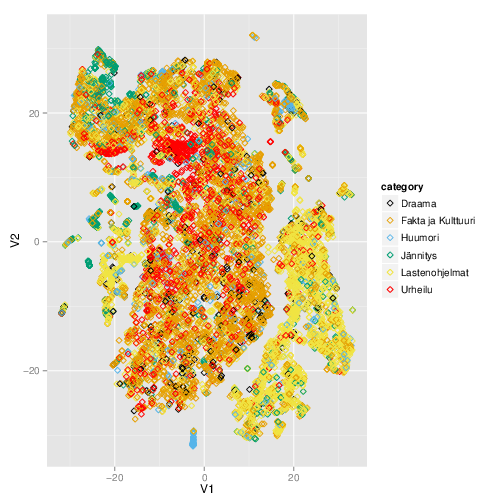
Toisaalta lastenohjelmakatastrofi myös motivoi pohtimaan, millä keinoin olisi mahdollista visualisoida katseluhistorioita ja suosituksia. Olisi hyödyllistä, mikäli jostain kuvasta voisi nähdä minkälaisia ohjelmia käyttäjä on katsonut, ja minkälaisia hänelle annetut suositukset ovat. Katseluhistorian visualisointi ei kuitenkaan ole aivan suoraviivaista, koska pienessäkin otoksessa on kymmeniä tuhansia ohjelmia ja satoja tuhansia käyttäjiä. Ensimmäinen yrityksemme näkyy kuvassa. Kuvassa pisteet ovat ohjelmia. Ohjelmien pitäisi olla ympyrän kaarella lähellä toisiaan, mikäli niitä ovat katsoneet samat käyttäjät. Etäisyys ympyrän keskipisteestä taas kertoo kuinka paljon katselukertoja kyseistä ohjelmaa ylipäänsä on katsottu. Esimerkkikuvissa lastenohjelmat ovat painottuneet vasemmalle, kun taas dokumentit ja ajankohtaisohjelmat ovat enemmän oikealla reunalla. Vaikka visualisointi siten tavoittaa jotakin ohjelmien eroista, se ei kuitenkaan ollut riittävän hyvä tarkoitukseensa. Kaarella nimittäin on vierekkäin täysin erilaisia ohjelmia, eikä siksi olisi juurikaan mahdollista sanoa sijainnin perusteella onko suosituksessa järkeä vai ei.

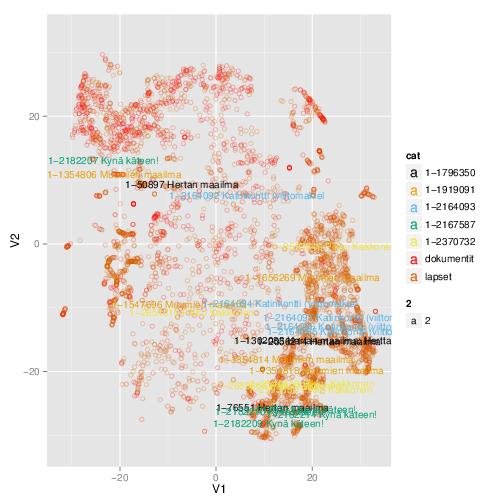
Seuraava yritys oli astetta kehittyneempi menetelmä nimeltään t-SNE (t-Distributed Stochastic Neighbor Embedding). Se tuotti hieman kiinnostavimpia tuloksia. Edelleen kuvassa vierekkäin ovat ohjelmat, joita ovat katselleet samat käyttäjät. Kuten kuvasta voi nähdä, lastenohjelmat erottuvat selkeästi omana klusterinaan. Samoin saman sarjan jaksot ovat yleensä lähellä toisiaan.
Kesä kuitenkin osoittautui yllättävän lyhyeksi, ja loppui hetkeä ennen kuin ehdimme selvittää lopullista ja kattavaa totuutta suosittelukoneista, moniulotteisten aineistojen visualisoinnista ja koneoppimisesta. Vaikka monta kiinnostavaa polkua jäikin tutkimatta, ehdimme kesän aikana oppia paljon suosittelukoneiden kehittämisestä. Erityisesti käytännön kautta tuli selväksi, että vaikka algoritmi löytyisi valmiiksi toteutettuna, sen kääriminen toimivaksi ohjelmointirajapinnaksi ei ole niinkään suoraviivaista. Itse puuhailimme kokeiluversion parissa, jonka ei ollut tarkoituskaan skaalautua kestämään todellisessa käytössä syntyviä kuormia. Sellaisenakin sen pystyttämiseen liittyi paljon omanlaisiaan teknisiä haasteita.