

Yle.fi hakukoneen tekninen toteutus
Aiemmassa blogauksessa käsittelin kevään aikana uudistuneen yle.fi hakukoneen uusia ominaisuuksia. Tämä postaus keskittyy tekniikkaan, jolla nämä ominaisuudet ja koko haku on toteutettu.
Suurin arkkitehtuurillinen muutos uudessa hakukoneessa on hakutulosten tuottamiseen ja näyttämiseen käytetyn tekniikan eriyttäminen. Tavoitteena eriyttämisessä on se, että pystymme kehittämään käyttöliittymää itsenäisesti, mutta ulkoistamaan sivujen indeksoinnin, analysoimisen, hakualgoritmien kehittämisen ja muun toiminnan, joka ei ole Ylen verkkokehitystiimin ydinosaamista. Eriyttämisen ansiosta voimme luoda käyttöliittymästä sellaisen, joka palvelee käyttäjiämme mahdollisimman hyvin ja sopii parhaiten juuri Ylen tarjoamille sisällöille. Voimme lisäksi mitata hakukoneen ja sen toimintojen käyttöä monipuolisemmin.
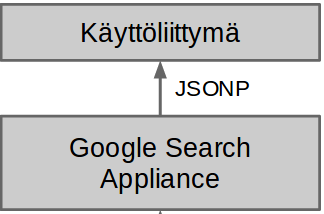
Hakukäyttöliittymä ja hakutulokset tuottava järjestelmä ovat siis täysin itsenäisiä ja erillisiä kokonaisuuksia, joista toista voidaan muuttaa tai se voidaan peräti vaihtaa ilman suuria muutoksia toiseen järjestelmään. Järjestelmät välittävät tietoa toisilleen HTTP-protokollaa käyttäen JSONP-formaatissa.
Hakutulokset tuotetaan käyttäen Google Search Appliance (GSA) tuotetta. GSA on käytännössä Googlen myymä palvelin, joka etsii, indeksoi ja analysoi kaiken Ylen sisällön sekä tuottaa hakutulokset annetuilla hakuparametreilla. Oletuksena GSA tuottaa myös hakutulossivun, mutta olemme määritelleet GSA:n tuottaman hakutulossivun sijaan hakutulokset JSONP-formaatissa. Tämä onnistuu GitHubista löytyvällä avoimen lähdekoodin GSA Frontend konfiguraatiolla, jota olemme kehittäneet eteenpäin.

Google Search Appliancen tuottama JSONP vastaus.
Hakukäyttöliittymä itsessään on toteutettu JavaScript-ohjelmointikielellä käyttäen angular.js-sovelluskehystä. Web-palvelin on toteutettu kahdennetulla node.js-palvelimella, jotka käyttävät myös express.js-sovelluskehystä mm. yle.fi ylä- ja alatunnisteen lisäämiseen sivulle. Valitut tekniikat ovat osoittautuneet hyviksi ja taanneet nopean käyttöliittymäkehityksen, helpon testattavuuden, hyvän skaalautuvuuden ja jatkuvan käyttöönoton.
GSA:n ja hakukäyttöliittymän lisäksi hakukone koostuu kolmannesta osasta jota kutsumme Crawl proxyksi. Käytännössä Crawl proxy on palvelu, joka tulkitsee ylen sisältöjä GSA:lle. Teknisesti Crawl proxy on node.js-palvelin, jonka kautta GSA:n tekemät HTTP-pyynnöt tehdään muihin Ylen palveluihin. Crawl proxy lukee kaikki sen läpi menevän HTML-merkkauksen ja lisää merkkaukseen elementtejä ennalta määritettyjen sääntöjen perusteella.
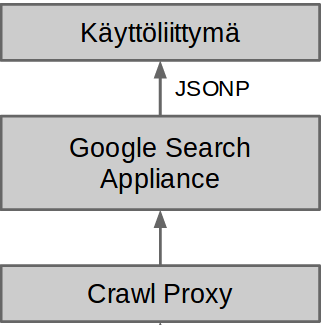
Crawl proxy lisää merkkaukseen mm. kielen, julkaisuajan, esikatselukuvan ja sisällön aiheen. Teoriassa GSA osaa itsekin päätellä artikkelin julkaisuajan ja kielen, mutta erilaisten merkkaustapojen ja aikaformaattien takia tämä ei käytännössä toimi yhtä hyvin kuin määrittely crawl proxyssä. Esikatselukuvat ja sisällön aiheet olisi mahdollista määritellä myös palveluissa kuten Yle Uutisissa ja Yle Areenassa, mutta koska määritystavat ovat pitkälti GSA:n omia emme halunneet lisätä näitä itse palveluihin.
Määritysten pitäminen crawl proxyssä pitää ylläpidon ja päivittämisen helppona ja keskitettynä, eikä muihin palveluihin tarvitse tehdä muutoksia. Näin voimme helposti parantaa ja lisätä GSA:n ominaisuuksia. Crawl proxy myös testaa automaattisesti Ylen muiden palveluiden HTML-merkkauksen niiltä osin kuin crawl proxylle on tarpeellista. Crawl proxy siis hälyttää mikäli jonkun palvelun HTML-merkkaus muuttuu niin että proxyn toiminta häiriintyy.
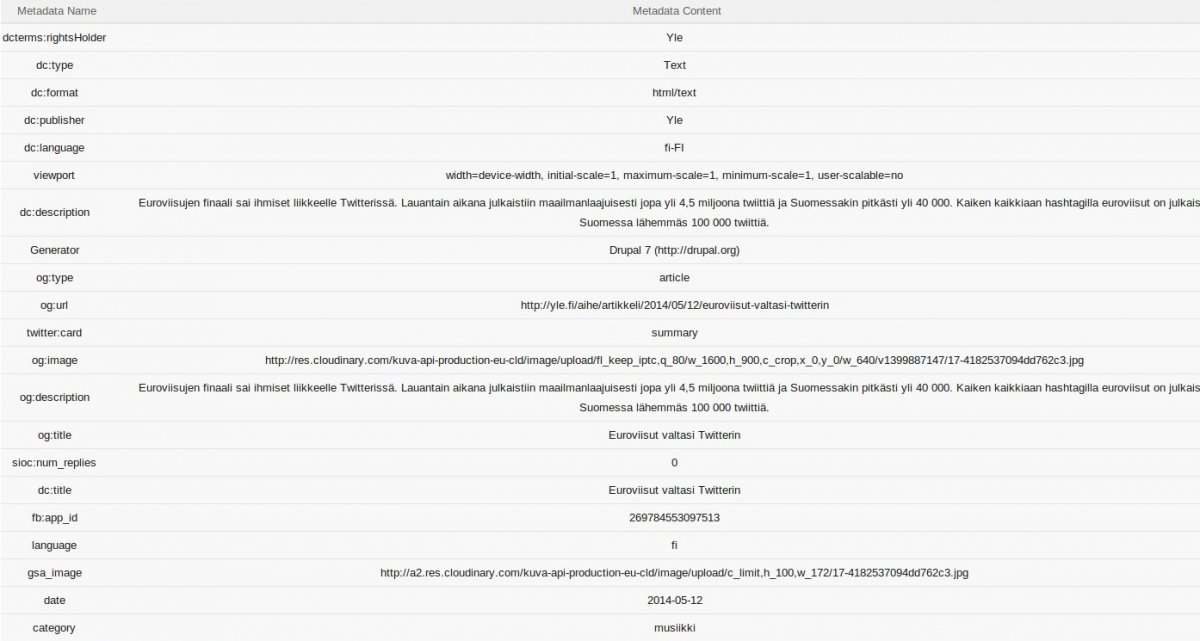
Google Search Appliancen tallentamaa metatietoa artikkelista. Osa tiedoista on crawl proxyn tuottamia.
Hakupalvelusta on haluttu tehdä mahdollisimman itsenäinen järjestelmä, joka ei riipu muiden järjestelmien sisäisestä toimintalogiikasta. GSA ei siis ole suoraan yhteydessä esimerkiksi Yle Uutisten tai Yle Areenan taustajärjestelmiin vaan lukee ainoastaan näiden julkisia verkkosivuja.
Hakupalvelu käyttää kuitenkin muutamia Ylen rajapintoja lisätoimintojen tuottamiseen. Esimerkiksi crawl proxy käyttää Ylen Images API:a kuvien pienentämiseen sopivan kokoisiksi esikatselukuviksi. Tulevaisuudessa rajapintojen kautta on tarkoitus tuoda lisää mielenkiintoisia toiminnallisuuksia. Tulevia toiminnallisuuksia voisivat olla mm. ohjelmatietojen haku, sosiaalisen medioiden jakomäärien näyttö, latausmäärien näyttö, jakomäärien ja latausmäärien käyttö hakualgoritmin optimoinnissa, jne.
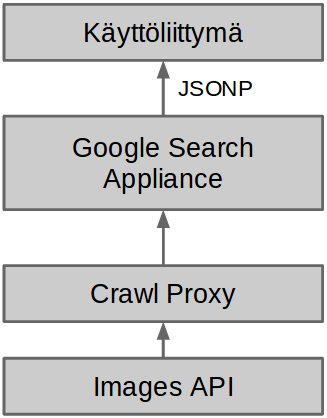
Hakukone koostuu siis useasta itsenäisestä moduulista, joiden tekniikka ja kehitys eivät ole riippuvaisia toisistaan. Hakukoneen modulaarisuus takaa sen että uusia moduuleja voidaan kehittää, lisätä ja poistaa ketterästi ja tehokkaasti. Nyt kun uudistuneen hakukoneen perusarkkitehtuuri on rakennettu ja todettu toimivaksi keskitymme hakukoneen eri osien ja toimintojen parantamiseen sekä uusien toimintojen lisäämiseen. Mikäli sinulla on ideoita miten hakua voisi kehittää voit kommentoida alle, lähettää sähköpostia osoitteeseen haku.ylefi@yle.fi tai tweetata @zeikko
